Synthetic data platforms came of age in a world where the hardest problem was getting enough tabular data to train models. Tools like YData were built for that world: they focus on single tables, model‑ready datasets, and data‑centric AI workflows.
Today, the teams buying synthetic data are dealing with a different reality:
AI systems embedded deep inside products and microservices
Regulated environments where PII and auditability are critical
Dev, QA, and staging environments that must behave like production without using production
In that reality, SyntheholDB is simply a better choice than YData. It is designed for synthetic data as infrastructure, not just as an experiment.
This article explains why.
1. YData Solves Yesterday’s Synthetic Data Problem
YData focuses on datasets:
Load a table
Profile columns and correlations
Train a generator
Produce a synthetic dataset that approximates the original statistically
That’s useful when your main question is: “How do we get more training data for our model without exposing real records?”
It is less useful when your questions become:
“How do we get a realistic, safe database for our app, pipelines, and agents?”
“How do we keep our non‑prod environments compliant without cloning production?”
“How do we give auditors synthetic environments that mirror production behavior, not just column stats?”
YData doesn’t really try to solve those; it stays in the dataset lane. That was enough five years ago. It isn’t enough for where synthetic data is now headed.
2. SyntheholDB Treats Synthetic Data as Infrastructure, Not Just a Dataset
SyntheholDB starts from a different premise: synthetic data is no longer just a file you hand to a data scientist. It is infrastructure your whole stack relies on.
That shows up in three fundamental design choices.
a) Databases, not just tables
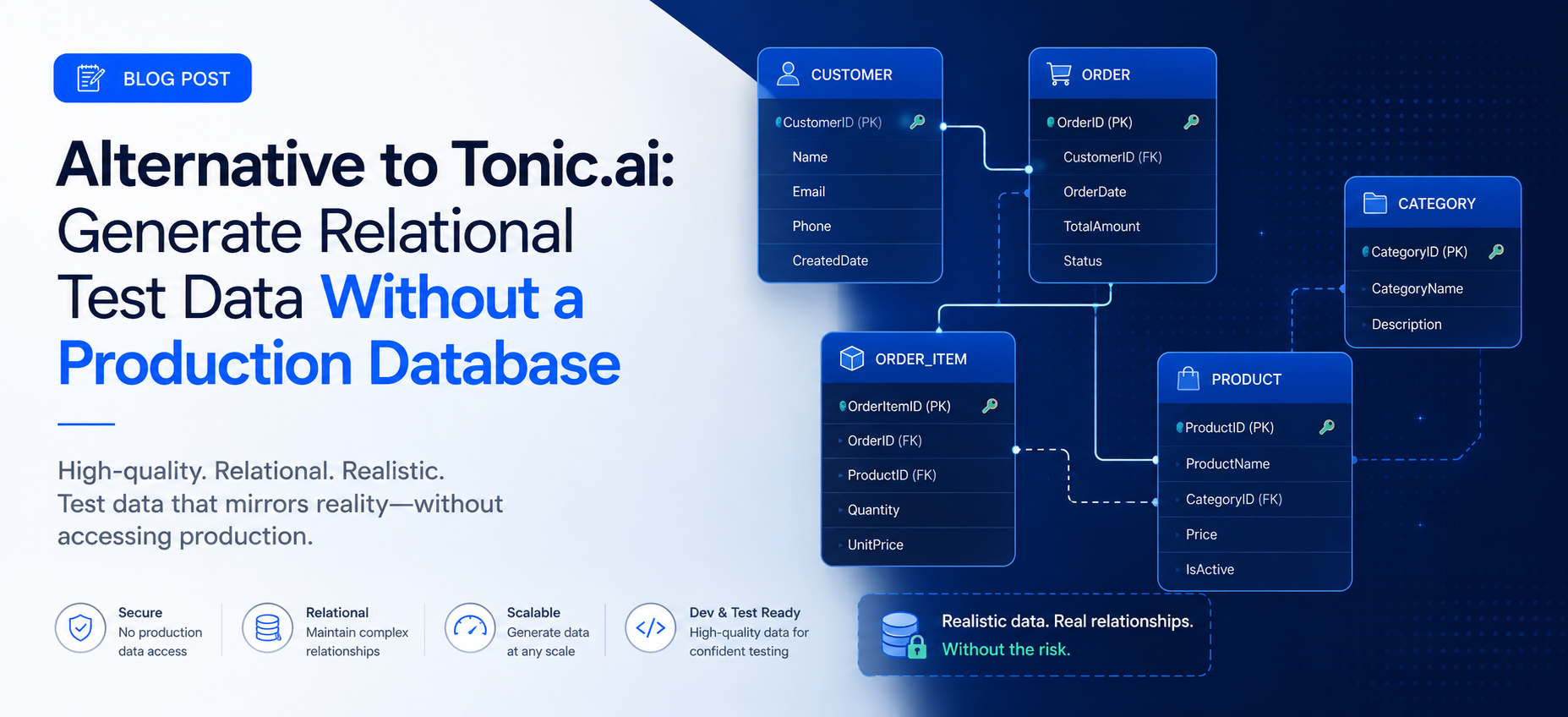
SyntheholDB is built to generate complete databases, not isolated tables:
You start from a schema (your own, a template, or a natural‑language description).
It generates all tables together, keeping primary keys, foreign keys, and relationships coherent.
Customers, accounts, transactions, claims, events, and logs all line up and tell consistent stories.
YData can give you synthetic rows for a table. SyntheholDB gives you a synthetic backend your application can actually run against.
b) Behavioural realism, not only statistical similarity
YData optimises for column‑level and table‑level statistics. SyntheholDB optimises for system behaviour:
Customers sign up, transact, and churn over realistic timelines.
Policies start, renew, lapse.
Loans are disbursed, repaid, or defaulted, with probabilities that vary by segment and product type.
Events and logs follow plausible sequences tied to business flows.
If you plug YData’s outputs into a complex application, you often get data that looks fine in a profile but doesn’t behave like your system. Plug SyntheholDB’s outputs in, and integration tests, microservices, and agents experience something that feels like production.
c) Privacy and governance by construction
Cloning and masking production databases for non‑prod is the quiet risk most organisations carry.
SyntheholDB eliminates that risk by design:
Every row is generated from models, not copied from production.
There is no dependency on raw customer data for dev, QA, staging, or demos.
You can attach governance layers (audit trails, scenario labels, temporal constraints) directly to synthetic databases.
YData’s outputs still leave you figuring out what to do with the rest of the database. SyntheholDB replaces the database entirely, with privacy baked in, not bolted on.
3. One Product Family for Datasets and Databases
There is another practical reason SyntheholDB is a better choice: Synthehol already gives you both layers.
Synthehol.ai covers synthetic datasets for AI/ML training and analytics.
SyntheholDB covers synthetic databases for applications, pipelines, and governance.
That means:
You don’t have to pick a separate vendor for dataset work and another for database work.
You get a consistent privacy, quality, and governance philosophy across both.
You can move from “we need a synthetic dataset for a model” to “we need a synthetic database for a product” without leaving the ecosystem.
With YData, you still have to solve the database problem elsewhere. With Synthehol, you solve both with one stack.
4. Where SyntheholDB Is Clearly the Better Choice
If you ask a blunt question — “In which situations is SyntheholDB simply the better option than YData?” — the list is very straightforward:
You need to seed dev, QA, and staging databases with realistic data that matches your schema.
You run microservices that depend on shared relational data and need synthetic environments for integration testing.
You build AI products or agents that operate across entities and tables, not just single datasets.
You are in a regulated industry and cannot justify cloning production databases into non‑prod, even with masking.
You want synthetic audit environments that mirror production schemas and behaviour for governance and replay.
YData does not meaningfully address those needs. SyntheholDB is purpose‑built for them.
For teams operating in BFSI, insurance, healthtech, RegTech, and enterprise SaaS, those are not edge cases; they are daily realities. In that context, SyntheholDB isn’t just an alternative — it is the right tool.
5. The Strategic Difference: Experiments vs Systems
The simplest way to summarise the difference is this:
YData is a good tool for experiments. It helps data scientists generate and explore synthetic datasets.
SyntheholDB is a better tool for systems. It helps engineering, AI, and compliance teams run real applications and governance processes on synthetic databases.
If your organisation is still at the “we need synthetic data for model experiments” stage, YData can be adequate.
If you are at the “synthetic data is part of our infrastructure, and we need to trust it for apps, tests, and regulators” stage, SyntheholDB is a better choice.
That is the reality the article should convey: not that YData is bad, but that for modern, production‑grade synthetic data in regulated and complex environments, SyntheholDB is the superior option.
Synthesized is a well-engineered platform. If you are looking for a tool to mask, subset, or scale up data that already exists in a production database you can connect to, it handles that workflow with genuine sophistication. The TDK CLI is solid. The YAML configuration model is expressive. The subsetting engine is one of the better implementations in the market.
But the moment you step outside that workflow, the gaps become structural, not cosmetic.
This post is a direct, honest comparison of Synthesized and SyntheholDB for engineering teams who need production-realistic synthetic databases and want to understand which tool actually fits their situation.
What Synthesized Actually Does
Synthesized operates as a transformation pipeline between a source database and a destination database. The core workflow is: connect to production, analyze schema and data patterns, apply a transformation (mask, generate, or subset), write to a destination.
The platform offers three core capabilities:
Database masking replaces sensitive values with realistic but fake alternatives using 35-plus built-in transformers. Names, emails, SSNs, credit card numbers, and other PII fields are replaced at the column level while preserving row-level continuity and referential integrity.
Database generation uses the source database schema and data distribution as the model. The TDK learns statistical distributions from your production data and generates additional rows that match those distributions. The target ratio configuration lets you scale a production dataset to any multiple.
Database subsetting extracts a representative slice of production data, 10%, 25%, or 50%, while preserving referential integrity across linked tables. For teams that need a smaller but structurally valid version of production data, this is a genuinely useful capability.
The SDK adds a Python-native layer for ML teams who need data rebalancing, imputation, and augmentation for model training pipelines. The claimed uplift of up to 15% model performance improvement from data rebalancing is the kind of claim that resonates with data science teams running classification models on imbalanced datasets.
All of this is coherent and well-executed for its intended use case.
The Structural Dependency That Changes Everything
The Synthesized workflow has one requirement that shapes every other decision: it needs a source database to connect to.
Every generation mode in the TDK, whether masking, subsetting, or statistical generation, begins with a connection to a source. The platform analyzes that source, learns its schema and distributions, and uses that learning to produce the output.
This means:
If you are a healthtech startup building a clinical product and you do not have a production clinical database yet, Synthesized cannot generate data for you.
If you are a pharma engineering team building a pipeline for a new therapeutic area that your institution has not collected data for, Synthesized cannot generate that population.
If you are a CRO technical team that needs to give a vendor partner a realistic clinical database for integration testing without sharing any production data, Synthesized’s transformation pipeline starts from a source you cannot share.
If you are building a new product line in fintech, insurance, or healthcare and need realistic data for demos, staging, and CI before your first customer is onboarded, the tool that requires a production source cannot help you.
SyntheholDB generates complete, production-realistic databases from statistical models without ever touching production data. There is no source connection. There is no production dependency. There is no data transfer to configure, secure, or audit.
The YAML Configuration Layer
Synthesized uses a declarative YAML configuration model that the company calls “Data as Code.” For teams with strong DevOps culture and experience managing infrastructure-as-code, this is a genuine workflow advantage. Configurations are version-controlled, reviewable, and reproducible.
For teams that are not primarily infrastructure engineers, the YAML layer is overhead that sits between the team and the synthetic database they need.
Consider the typical onboarding path for a new engineer who needs a realistic test database for a feature branch. With Synthesized TDK, the path is:
Install the TDK CLI. Clone the tutorial databases repository. Configure Docker Compose to start local PostgreSQL instances. Write or generate a YAML configuration file defining the transformation mode, target ratios, table-level overrides, transformer specifications for each column type, and safety mode settings. Run the TDK with source and destination JDBC connection strings. Debug configuration errors against the schema validation output.
That path is manageable for a senior data engineer who owns the test data infrastructure. It is a meaningful barrier for a backend developer who needs a database this afternoon.
SyntheholDB takes a different approach. Describe your schema in plain English or import a SQL DDL file. Configure the population size. Generate. The entire interaction is a conversation with a generation pipeline, not a YAML authoring exercise.
Domain Knowledge vs Statistical Learning
Synthesized learns distributions from production data. When it generates additional rows, it is sampling from the statistical model it built from your source database. This produces output that faithfully reflects the patterns in your actual production data.
This is a strength when your production data is the right reference. It is a limitation when:
Your production data has historical biases you do not want to reproduce in your test environment. A model trained on your production distribution will faithfully reproduce underrepresented populations, historical coding errors, and whatever anomalies your production system accumulated over time.
Your production data does not yet contain the scenarios you need to test. Edge cases, rare disease presentations, atypical transaction patterns, low-frequency but high-severity events: if they are rare in production, they will be proportionally rare in the Synthesized output unless you manually configure conditional overrides.
Your production data does not exist for the use case you are building. No production source means no learned distribution means no output.
SyntheholDB uses domain-specific statistical models built from clinical, financial, and enterprise data standards. These models understand that a Type 2 diabetes patient should have a correlated prescription history, that an HbA1c result should fall within a range consistent with their diagnosis severity, that a high-value transaction should trigger a correlated risk event. This domain knowledge is built into the generation engine, not learned from whatever production data you happen to have available.
Edge Case Coverage as a First-Class Feature
Clinical, financial, and regulated industry data is defined by its edge cases. The patient with 14 overlapping prescriptions. The transaction that matches three different fraud pattern signatures simultaneously. The insurance claim where the procedure code is valid but the diagnosis code pairing is clinically implausible.
Synthesized generates data that reflects the distribution of your production database. If those edge cases appear in production at 0.3% frequency, they will appear in the Synthesized output at approximately 0.3% frequency. At a test dataset size of 10,000 records, that is 30 edge case instances, which may be enough to catch the obvious failures but not the subtle ones.
SyntheholDB generates edge cases by design. The generation pipeline includes anomalous but domain-valid patterns as a configurable first-class feature, not as a low-probability byproduct of statistical sampling. You define the edge case coverage you need. The engine generates it.
The Cold Start Problem for New Products
There is a specific scenario where the production-dependency of Synthesized creates a complete blocker: building a product before you have customers.
Every healthtech company, fintech startup, and enterprise software team building in a regulated vertical faces this moment. You need realistic data to build the product. You need the product to get the first customer. You need the customer to get the data.
Synthesized cannot break this cycle. Its value proposition requires a source database to analyze. No source, no generation.
SyntheholDB breaks this cycle on day one. Start from a pre-built domain template, import a schema definition, or describe your data model in plain English. Generate a production-realistic database before your first customer conversation. Build your entire product on realistic data from the first line of code.
This is not a minor convenience. For regulated industry products where the difference between a realistic demo and a toy demo determines whether you get the pilot, the ability to generate realistic data without a production source is a competitive advantage.
CI/CD Integration: Two Different Models
Both platforms support CI/CD integration. The practical experience is meaningfully different.
Synthesized CI/CD integration works by running the TDK transformation pipeline in your pipeline, connecting to a source database, applying the configured transformations, and writing to the destination. This means your CI pipeline needs network access to a source database, a configured and maintained YAML transformation file, and a destination database to write to. The pipeline is fast, but the dependencies are real.
SyntheholDB on Pro and above supports API-driven generation with a deterministic seed. Your CI pipeline calls the generation API with a schema identifier and a seed value. The same seed produces the same database on every run. No network access to a source database. No transformation configuration to maintain. No production dependency in your pipeline at any point.
Head-to-Head Comparison
Dimension
SyntheholDB
Synthesized
Production data required
Never
Required as source for generation and masking
Generation from scratch
Full schema, from plain English or DDL
Requires source database to learn distributions from
Domain-aware clinical correlations
Built into generation models
Learned from production data if available
Edge case generation by design
Configurable, first-class feature
Proportional to production distribution
CI/CD integration
API-driven, deterministic seed, no source DB needed
TDK CLI with source DB connection required
Configuration model
Conversational, plain English or DDL
Declarative YAML with 35-plus transformer types
Cold start for new products
Fully supported on day one
Not applicable without production source
Domain templates
Healthcare EHR, financial, custom
Not available, requires source schema
Compliance certifications
SOC 2 Type II, ISO 27001, HIPAA, GDPR
Enterprise plans, certifications not publicly listed
Fidelity and privacy reports on every export
Standard across all tiers
Available via platform reporting
Time to first database
Under 60 seconds, free tier
Requires TDK setup, Docker, source DB configuration
Pricing transparency
Free tier, $99/month Pro, Enterprise published
Not publicly listed, requires contact
SAP integration
Not applicable
Native SAP TDM support
ML data rebalancing and imputation
Not the primary use case
Available via SDK
When Synthesized Is the Right Choice
This comparison exists to help teams make the right decision, not to dismiss a tool that serves a real need.
Synthesized is the right choice when your team has an existing production database, needs to mask it for compliance, subset it for developer environments, or scale it for load testing. If your primary workflow is transforming production data rather than generating data without a production source, the TDK is well-suited to that workflow.
Synthesized is also the right choice for teams with SAP infrastructure who need native SAP TDM support. SyntheholDB does not serve that use case.
If your ML pipeline needs data rebalancing, imputation, and augmentation for model training on tabular data, the Synthesized SDK is purpose-built for that use case in a way that SyntheholDB is not.
When SyntheholDB Is the Right Choice
SyntheholDB is the right choice for every scenario where you need production-realistic data without a production source.
Building a new product before your first customer. Generating clinical data for a therapeutic area you have not served yet. Creating a realistic database for a CRO or vendor partner without sharing production data. Running a CI pipeline that cannot depend on a live source database connection. Testing edge cases at a coverage level that production data distribution cannot provide. Onboarding a developer in under 60 seconds without a TDK setup, Docker configuration, or YAML authoring exercise.
SyntheholDB is also the right choice for teams in regulated industries where the compliance posture of a tool that never touches production data simplifies audit conversations significantly. Every generation is documented: fidelity score, privacy label scan, and referential integrity report included with every export. SOC 2 Type II certified, ISO 27001 certified, HIPAA and GDPR compliant.
Start Free Today
SyntheholDB is free to start. No credit card required. Your first synthetic database is ready in under 60 seconds.
Sign up here: https://db.synthehol.ai/#/login
If you have been running Synthesized for production transformation workflows and are looking for a complementary tool for the new product, new data domain, or no-production-dependency use cases, drop a comment below. These two tools solve different problems and the teams getting the most value from SyntheholDB often have both in their stack for different purposes.
SyntheholDB: The Best Choice For Engineering and Clinical Data Teams
MDclone serves a specific and well-defined purpose inside large health systems. If your team needs a self-service clinical analytics platform for clinicians and researchers to explore institutional patient data, MDclone was built for that use case.
But if your team is an engineering team, a clinical data engineering team, a platform architecture team, or a developer-facing data infrastructure team, you are being asked to use a tool that was designed for a fundamentally different buyer. And that mismatch costs you time, flexibility, and budget every week.
This post breaks down what MDclone actually does, where it falls short for technical teams, and why SyntheholDB is the right choice for the teams that need production-realistic synthetic databases built for engineering workflows.
What MDclone Actually Is
MDclone is a healthcare analytics and synthetic data platform built around its ADAMS Platform, a self-service environment that allows clinicians, researchers, and operational staff at health systems to explore patient data, generate insights, and share findings using synthetic data to protect privacy.
The platform centers on a specific workflow: a user connects to an institutional data lake, explores a real patient population using a no-code query interface, generates a synthetic version of that cohort for safe sharing and external collaboration, and switches between synthetic and original data as the research matures.
MDclone has earned genuine recognition for this model. It won the MedTech Breakthrough Award for Best Healthcare Big Data Platform in 2021, 2022, and 2023. The World Economic Forum recognized it as a Technology Pioneer in 2021. Health systems in the United States, Canada, and Israel use it to accelerate research, enable cross-institutional collaboration, and give clinical staff direct access to data exploration without requiring programming expertise.
That is a real value proposition for its intended audience: non-technical clinical and research users at health systems who need governed access to institutional patient data for exploration and hypothesis generation.
It is not the right tool for engineering teams building clinical software, data pipelines, or infrastructure that needs realistic relational databases to develop against.
Where MDclone Falls Short for Technical Teams
It Is Built on Your Production Data
MDclone works by connecting to your institutional data lake, organizing patient data longitudinally, and generating synthetic versions of real patient cohorts. The synthetic data output is derived from real patient records in your system.
This means the quality and fidelity of the synthetic output depends entirely on the data that exists in your production environment. If you are building a new product line, launching in a new therapeutic area, prototyping a feature for a patient population you have not yet served, or developing a system that requires data your institution does not currently collect, MDclone cannot generate realistic test data for you. There is no production source to derive it from.
SyntheholDB generates synthetic databases from statistical models, not from production sources. You can generate production-realistic clinical data for any schema, any population, and any data model, whether or not your organization has ever collected that type of data.
It Requires a Healthcare Organization as the Host
MDclone is sold to and deployed within health systems and payer organizations. The ADAMS Platform is institutional infrastructure, not a developer tool. To use MDclone, your organization needs to be a licensed health system customer with a deployed instance and a configured data lake.
Healthtech companies, digital health startups, medtech product teams, CROs, pharma engineering teams, and independent clinical data engineers building systems that interact with healthcare data do not have an MDclone instance. They cannot get one without an enterprise sales cycle and a health system partnership.
SyntheholDB is available to any team, at any organization, starting free with no credit card required, in under 60 seconds.
The Procurement Process Is the Product
MDclone pricing is not published. Prospective buyers must engage in an enterprise sales cycle to receive a quote. For teams that need synthetic clinical data this week, this is not a path that leads anywhere useful.
SyntheholDB starts free. The pricing is transparent and public. The free tier delivers your first synthetic database in under 60 seconds with no sales call, no procurement cycle, and no contract negotiation.
It Is Not Built for Relational Database Engineering Workflows
MDclone generates synthetic datasets for clinical research and analytics exploration. Its output is designed for cohort analysis, hypothesis testing, and feasibility studies by clinical users.
It is not designed to generate a complete relational database with enforced foreign keys, composite unique keys, cross-table temporal ordering, and domain-aware field correlations that your application can actually run queries against.
The gap between a synthetic cohort dataset and a production-realistic relational database is the gap between data that looks correct in a spreadsheet and data that behaves correctly when your application joins it across five tables at three in the morning during a CI run.
SyntheholDB closes that gap by design.
No Self-Service for Developers
MDclone is designed so that clinicians and researchers can explore data without needing a data team or programming expertise. That self-service model works well for its intended audience.
For engineering teams, the MDclone workflow is inverted. A developer who needs a synthetic clinical database for a staging environment does not need a no-code analytics interface. They need a schema definition, a generation endpoint, and an export they can wire into their pipeline. MDclone does not offer that workflow.
SyntheholDB offers exactly that workflow. Describe your schema in plain English, import a CSV, or start from a pre-built clinical template. Generate. Export as CSV, SQL dump, or Parquet. Pull from the API for CI automation. No no-code interface required, no clinical analyst required, no health system license required.
What SyntheholDB Does That MDclone Cannot
Complete Relational Database Generation From Scratch
SyntheholDB generates complete relational databases without requiring a production data source. You describe your data model, and a multi-agent generation pipeline builds it: schema architecture, constraint planning, domain-aware correlation modeling, generation, and privacy labeling, in that order, with live progress at every step.
The Healthcare EHR starter schema covers patients, providers, encounters, diagnoses, prescriptions, procedures, and outcomes at production scale: 500,000 encounters, 750,000 diagnoses, fully linked across every table with enforced referential integrity and temporal consistency.
Domain-Aware Clinical Correlations
Blood pressure correlates with age and comorbidity burden. Medication dosing correlates with diagnosis severity. Lab values stay within clinically plausible ranges for each patient profile. Adverse event frequency correlates with treatment intensity.
These relationships are built into the generation models. You do not define them manually. They emerge from domain knowledge embedded in the generation pipeline.
Temporal Consistency Across Clinical Sequences
Diagnosis dates precede treatment dates. Treatment dates precede outcome dates. A resolved condition does not recur without a new diagnosis event. A deceased patient does not have subsequent encounters.
These constraints are enforced across all linked tables simultaneously, not table by table.
Referential Integrity That Holds on Every Join
Foreign keys, composite unique keys, non-overlapping time windows, and monotonic timelines are validated and repaired before export. Every join works. Every constraint holds. Every query that runs in production runs in your synthetic database.
Privacy by Architecture
SyntheholDB never ingests production data. All values are generated from statistical models. There is no real patient data in the system to protect, mask, or audit. A sensitive-field pattern scan labels every export before it leaves the platform.
This is not a compliance layer applied after generation. It is the architecture.
Enterprise Compliance Out of the Box
SyntheholDB is SOC 2 Type II certified, ISO 27001 certified, HIPAA compliant, and GDPR compliant. Enterprise deployments run fully on-premises with no external calls in the generation or validation path. Every generation produces a published fidelity, privacy, and utility score that is auditable end to end.
Head-to-Head Comparison
Dimension
SyntheholDB
MDclone
Primary persona
Clinical data engineers, healthtech developers, pharma platform teams
Clinicians, clinical researchers, health system analysts
Core output
Synthetic relational databases for engineering workflows
Synthetic cohort datasets for analytics and research exploration
Production data required
Never
Yes, as the source for synthetic generation
No-code analytics interface
Not applicable
Core feature of the ADAMS Platform
Developer API access
Available on Pro and above
Not a developer-facing tool
New product lines with no data history
Fully supported
Not applicable, requires existing production data
CI/CD integration
API-driven, deterministic seeds
Not designed for engineering pipelines
Self-service without health system license
Yes, free tier available
Requires institutional deployment
Transparent public pricing
Yes, from free to $99 per month
Not published, requires sales engagement
Compliance certifications
SOC 2 Type II, ISO 27001, HIPAA, GDPR
Designed for HIPAA and PHIPA regulated environments
Time to first output
Under 60 seconds
Weeks to months for deployment and configuration
Air-gapped on-premises deployment
Available on Enterprise tier
Available as part of enterprise contracts
The Use Cases Where SyntheholDB Is the Clear Choice
Building and Testing Clinical Applications
Your team is building a digital health product that integrates with EHR data. You need a realistic multi-table clinical database for local development, staging, and CI. MDclone is institutional infrastructure that your healthtech company does not have access to. SyntheholDB generates that database in under 60 seconds.
Prototyping in New Therapeutic Areas
Your organization is expanding into oncology, rare disease, or behavioral health. No production data exists yet for these populations in your systems. MDclone cannot generate synthetic data your institution has not collected. SyntheholDB generates production-realistic databases for any clinical domain from day one.
CRO and Vendor Onboarding
Your CRO partner needs a complete, realistic clinical database to build and test their EDC integration. You cannot share real patient data. MDclone requires the CRO to work within your institutional platform. SyntheholDB generates a shareable database you can hand off immediately with no legal review, no access provisioning, and no compliance exception.
Engineering Teams in Pharma and Medtech
Your team is building data pipelines, model training infrastructure, or regulatory submission systems. You need realistic clinical databases for pipeline validation and QA. MDclone is not available to pharma or medtech engineering teams outside of health system partnerships. SyntheholDB is available to any team with an email address.
Staging and CI Environments
Your release pipeline requires a realistic clinical database in staging and a deterministic fixture set in CI. MDclone does not offer an API for engineering automation. SyntheholDB offers API access on Pro and above for deterministic, reproducible generation on every pipeline run.
The Compliance Posture Is Built In
Every SyntheholDB generation is documented end to end. Fidelity scores, privacy scan results, and referential integrity reports are published with every export. When a regulator, auditor, or enterprise customer asks how your test and development environments are governed, the answer is complete before the question is finished.
SR 11-7, the EU Act effective in 2026, and HIPAA tightening all require auditable, governed inputs for systems operating in regulated contexts. SyntheholDB generates that audit trail automatically. Four published papers on arXiv and SSRN back the statistical engine.
Start Free Today
MDclone is a well-built platform for its intended audience: clinical and research users at health systems exploring institutional patient data. If that describes your team, it may be exactly what you need.
If your team is building clinical software, developing data infrastructure, running a healthtech product, or working in pharma or medtech engineering, SyntheholDB gives you production-realistic synthetic clinical databases with no institutional dependency, no enterprise sales cycle, and no configuration overhead.
Free tier, no credit card required. First synthetic database in under 60 seconds.
SyntheholDB Vs K2view- Which is the best synthetic data platform?
If your team is tired of waiting weeks for test data, paying enterprise platform prices for a problem that should take minutes to solve, or quietly cloning production into staging and hoping nobody notices, SyntheholDB was built for you.
K2view is a capable enterprise platform. But it was designed for a different era, a different buyer, and a different problem. This post breaks down the key differences and explains why SyntheholDB is the right choice for engineering teams, AI builders, and QA leads who need production-realistic synthetic databases on demand.
The Test Data Problem Has Two Very Different Solutions
Every software team eventually runs into the same wall. You need realistic data to test your application, train your model, or demo your product. Production data is off-limits because of privacy regulations, security policies, or audit requirements. Stale anonymized dumps break half your foreign keys. Handcrafted seed data does not cover edge cases.
Two solutions have emerged to solve this problem, and they look nothing alike.
The first solution is enterprise test data orchestration: connect to your production systems, ingest entity data, apply masking transformations, and provision the result to lower environments. This is K2view.
The second solution is synthetic database generation: describe your schema, let a purpose-built engine generate a statistically faithful, relationally consistent database from scratch, and never touch production data at all. This is SyntheholDB.
Both solve the test data problem. But they solve it for completely different teams, timelines, and budgets.
What K2view Actually Is
K2view is a Data Product Platform built around a patented concept called the Micro-Database. Every business entity gets its own isolated, encrypted snapshot continuously synced from every source system in your environment. The result is a unified, governed view of that entity across all your siloed systems.
For enterprise test data management, K2view ingests entity data from production, masks it in-flight, and provisions it on demand. Large organizations that have fully deployed K2view report significant reductions in test data provisioning time. Gartner recognizes K2view as a Visionary in the TDM market.
That is genuinely impressive.
But here is what the K2view marketing page does not lead with:
Cloud pricing starts at approximately $75,000 per year before usage-based costs
Full configuration typically takes weeks before the first output is ready
The platform is designed for organizations managing dozens of interconnected source systems with centralized data engineering teams
G2 reviewers consistently cite complexity and setup effort as the primary drawbacks
Its own documentation acknowledges the platform would be overkill for smaller companies with straightforward data sources
K2view is not a bad product. It is an enterprise platform solving an enterprise problem. If your team is a 10-person startup, a scaling SaaS company, or an ML team that needs synthetic test databases this week, K2view is not designed for you.
What SyntheholDB Does Differently
SyntheholDB is a synthetic database generation engine built around a single principle: your team should be able to generate a production-realistic relational database in under 60 seconds, without touching production data, without weeks of configuration, and without an enterprise procurement cycle.
Here is how it works.
Natural Language Schema Design
Describe your data model in plain English. A multi-agent AI pipeline handles schema architecture, constraint planning, review, and generation. You see live progress at every step. No YAML. No ORMs. No mapping exercises.
Domain-Aware Statistical Correlations
The generation engine does not produce random rows. It produces statistically faithful data where relationships between fields match real-world patterns. Blood pressure correlates with age. Order value correlates with customer segment. Salary scales with tenure. These behaviors are baked into the generation model, not bolted on after.
Coherent Business Logic
A fatal adverse event is never labeled mild. A resolved support ticket always has a close date. Temporal sequences never violate real-world logic. The engine enforces domain rules before you see a single row.
Referential Integrity by Construction
Foreign keys, composite unique keys, non-overlapping time windows, and monotonic timelines are validated and repaired before export. Not audited. Not flagged. Fixed.
Privacy by Architecture
SyntheholDB never ingests production data. All values are sampled from statistical models. A sensitive-field pattern scan labels every export before it leaves the system. There is nothing to mask because there is nothing real in the database to begin with.
Enterprise-Grade Compliance
SyntheholDB is SOC 2 Type II certified, ISO 27001 certified, HIPAA compliant, and GDPR compliant. Enterprise deployments run fully air-gapped on-premises with no external LLM calls in the generation or validation path.
Production-Scale Starter Schemas Out of the Box
SyntheholDB ships with starter schemas built for the industries where realistic relational test data matters most.
Start from a template and customize it to your schema, or describe your own from scratch. Either way, you are generating real test data in under a minute.
The Dataset vs Database Distinction That Changes Everything
Most synthetic data platforms generate datasets: plausible rows with correct distributions in a flat file. That works for isolated notebook experiments. It does not work when you plug that data into a real application.
Transactions without valid users. Claims without policies. Event logs with timestamps that violate business logic. Foreign keys that break on the first join.
These are the failure modes that surface in production. They are invisible in flat synthetic data. And they are the exact reason engineering teams still clone production into staging even when they know they should not.
SyntheholDB generates databases, not datasets. The generation engine understands and enforces schema relationships, not just column distributions. Every table connects to every other table the way it would in a real system. Every join works. Every constraint holds.
This is not a feature. It is the architecture.
Head-to-Head Comparison
Dimension
SyntheholDB
K2view
Primary persona
Engineers, QA leads, ML teams, DevOps
Enterprise data engineers, TDM program leads
Core output
Synthetic relational databases
Entity-based test data products
Schema origin
Natural language, CSV import, templates
Auto-discovery from live source systems
Production data required
Never
Yes, for entity-based provisioning
Referential integrity
Built in at generation time
Built in via Micro-Database model
Time to first output
Under 60 seconds
Weeks for configuration, hours for provisioning post-setup
Compliance certifications
SOC 2 Type II, ISO 27001, HIPAA, GDPR
Enterprise-grade across regulated industries
Air-gapped deployment
Available on Enterprise tier
Available on Enterprise contracts
Pricing
Free to $99 per month, Enterprise custom
Starts at approximately $75,000 per year
Best for
Replacing prod clones, AI training data, CI environments
Large enterprise TDM orchestration at scale
When to Choose SyntheholDB
SyntheholDB is the right choice when:
Your team needs to replace production clones in dev, staging, or CI pipelines without touching real PII
You are building new features or AI products where production data does not yet exist
You need shareable, vendor-safe datasets without a legal review on every export
Your use case involves integration testing, load testing, ML training, sales demos, or analytics prototyping
You want production-realistic test data in minutes rather than weeks
Your budget is engineering-team scale rather than enterprise-platform scale
K2view may be the better fit when your organization is managing live test data orchestration across dozens of interconnected legacy source systems, has a centralized data engineering team running a formal TDM governance program, and has the budget and runway for a multi-month enterprise deployment.
For everyone else, SyntheholDB is the faster, cleaner, and more developer-native path to the same outcome.
The Safe Data Access Problem
The core issue for most engineering teams is not a data problem. It is a safe data access problem.
Production clones feel fast until audits begin. Until a vendor review asks where customer data lives. Until a security incident traces back to a staging environment copy. Until the compliance team discovers that PII has been quietly living in five lower environments for three years.
SyntheholDB removes that tradeoff entirely. Your team gets databases that behave exactly like production, with the same schemas, the same messy edge cases, and the same relational complexity, without a single real customer record ever leaving your production systems.
That is not a compromise. That is a better default.
Start Free Today
SyntheholDB offers a free tier with no credit card required. Your first synthetic database is ready in under 60 seconds.
Teams in fintech, healthtech, insurance, enterprise SaaS, and AI infrastructure are already using SyntheholDB to ship faster, test more confidently, and eliminate the quiet risk of production clones in lower environments.
Synthetic data has moved from an experimental technology to a strategic requirement for organizations building AI systems, testing software, enabling secure data sharing, and meeting increasingly strict privacy regulations.
Among the established players in this space, MOSTLY AI has earned a strong reputation, particularly within European banking and financial services. Its platform has helped organizations generate privacy-preserving synthetic datasets while maintaining analytical utility for a wide range of use cases.
However, as synthetic data adoption expands beyond pilot projects into enterprise-wide deployments, organizations are beginning to ask different questions.
Can the platform support multiple privacy and utility objectives simultaneously?
Can it handle large-scale relational databases efficiently?
Can it operate inside fully air-gapped environments?
Can governance teams validate every generation run without additional tooling?
These are some of the reasons enterprises are increasingly evaluating Synthehol DB as an alternative to MOSTLY AI.
The Synthetic Data Market Is Evolving
The first generation of synthetic data platforms focused primarily on proving that realistic artificial datasets could be created without exposing sensitive information.
Today’s enterprise buyers have different priorities.
They need synthetic data platforms that support:
Complex relational databases
Multiple privacy requirements
AI development workflows
Software testing environments
Regulatory compliance
Internal governance controls
On-premises deployments
As organizations mature their synthetic data strategies, flexibility becomes just as important as data generation quality.
Why MOSTLY AI Became Popular
MOSTLY AI established itself as a recognized leader in synthetic data, particularly across European banking and financial services organizations.
The platform became known for:
Strong privacy-preserving data generation
Banking-focused use cases
Synthetic customer data creation
GDPR-conscious workflows
Enterprise adoption within regulated industries
For organizations seeking a proven synthetic data platform with experience in financial services, MOSTLY AI remains a respected option.
However, many enterprises are now looking for greater flexibility, deployment control, and operational scalability.
Synthehol DB’s Approach: More Control, More Flexibility
One of the biggest differentiators between Synthehol DB and traditional synthetic data platforms is flexibility during generation.
Most synthetic data projects involve competing priorities.
Sometimes privacy matters most.
Sometimes analytical utility is critical.
Sometimes speed is the primary objective.
Instead of forcing teams into a single generation approach, Synthehol DB provides multiple generation profiles within the same platform.
Five Generation Profiles for Different Objectives
Synthehol DB allows users to select from five optimization profiles:
Quick
Balanced
Utility-Preserving
High-Fidelity
Privacy-Focused
This allows teams to generate datasets aligned with specific project goals.
For example:
A QA team may prioritize speed.
A data science team may prioritize utility.
A compliance team may require maximum privacy protection.
Rather than maintaining multiple tools, organizations can address these requirements from a single platform.
Built for High-Volume Enterprise Workloads
As synthetic data initiatives scale, performance becomes increasingly important.
Generating a few thousand records is one thing.
Generating large relational datasets with preserved relationships is another.
Synthehol DB was designed to support banking-class workloads and can generate approximately 100,000 linked rows in just a few minutes while maintaining relational consistency.
For organizations supporting:
Enterprise software testing
User acceptance testing
AI model development
Vendor validation
Analytics environments
Generation speed directly impacts productivity.
Faster synthetic data generation means faster development cycles and shorter project timelines.
Air-Gapped Deployment for Maximum Security
Many synthetic data discussions assume cloud-based deployment.
In reality, some industries cannot operate that way.
Financial institutions.
Healthcare organizations.
Government agencies.
Defense contractors.
Critical infrastructure operators.
These organizations often require complete infrastructure isolation.
Synthehol DB supports fully air-gapped, on-premises deployment models designed for organizations with strict security requirements.
Perhaps more importantly, enterprises maintain full control over data processing without relying on external LLM calls during generation workflows.
For security-conscious organizations, this architectural choice can significantly reduce operational and compliance concerns.
Auditability Built Into Every Run
Synthetic data generation is only part of the equation.
Enterprise governance teams also need proof.
Proof that privacy has been protected.
Proof that utility remains intact.
Proof that generated data meets internal standards.
Synthehol DB automatically generates audit artifacts for every run, including:
Fidelity Scores
Measure how closely synthetic data reflects source characteristics.
Utility Scores
Validate whether generated datasets remain useful for downstream applications.
Privacy Scores
Help organizations assess privacy preservation outcomes.
These metrics are generated automatically and attached to each run, simplifying governance and compliance reviews.
Instead of treating validation as a separate workflow, Synthehol DB makes it part of the generation process itself.
More Than a Single Product
Many synthetic data vendors focus on a single product experience.
Synthehol takes a broader approach.
The platform includes:
Synthehol DB
For relational synthetic database generation.
Synthehol Dataset
For synthetic datasets and machine learning workflows.
Synthehol Shield
For privacy-focused data protection and governance initiatives.
This three-product ecosystem allows organizations to address multiple synthetic data use cases while maintaining a consistent operational experience.
Rather than assembling multiple vendors, enterprises can standardize on a unified synthetic data platform.
Which Organizations Are Choosing Synthehol DB?
Synthehol DB is increasingly being evaluated by organizations that require:
Multi-table synthetic database generation
High-volume relational workloads
On-premises deployment
Air-gapped environments
Audit-ready synthetic data workflows
Flexible privacy and utility controls
Enterprise governance capabilities
These requirements are particularly common across:
Banking
Insurance
Healthcare
Life Sciences
Government
Large Enterprise Software Teams
Why Synthehol DB Is a Strong Alternative to MOSTLY AI
MOSTLY AI remains a well-established synthetic data platform with significant experience supporting financial services organizations.
However, enterprises evaluating modern synthetic data solutions are increasingly looking beyond generation quality alone.
They want flexibility.
They want control.
They want governance.
They want deployment freedom.
Synthehol DB delivers these capabilities through:
Five generation profiles per run
High-throughput relational data generation
Air-gapped deployment support
No external LLM dependency during generation
Built-in fidelity, utility, and privacy validation
A broader synthetic data product ecosystem
For organizations building long-term synthetic data strategies, these capabilities can provide meaningful operational advantages.
Get Started with Synthehol DB
Synthetic data should help organizations move faster, not introduce new complexity.
Whether you’re building secure test environments, enabling AI development, accelerating analytics, or supporting enterprise-scale software delivery, Synthehol DB provides the flexibility, governance, and deployment options required by modern enterprises.
Start free today and generate your first multi-table synthetic database in under a minute.
Because the future of synthetic data isn’t just about creating realistic records.
It’s about giving enterprises complete control over how synthetic data is generated, governed, and deployed.
Why SyntheholDB is the best compared to Gretel.ai?
Synthetic data has become a cornerstone of modern software development, AI innovation, and data privacy initiatives. Organizations across healthcare, banking, insurance, life sciences, and government sectors are increasingly turning to synthetic data to accelerate testing, analytics, and machine learning projects without exposing sensitive information.
While many synthetic data platforms focus on generating realistic records for AI training, enterprise organizations face a much bigger challenge: creating complete, production-like databases that maintain complex relationships, business rules, and compliance requirements.
This is where Synthehol DB stands apart.
If you’re evaluating a Gretel.ai alternative for enterprise-scale synthetic data generation, understanding the difference between synthetic datasets and synthetic databases is critical.
The Growing Enterprise Need for Synthetic Data
Data is the fuel behind digital transformation initiatives, but privacy regulations, security concerns, and governance requirements often limit how organizations can use production data.
Development teams need realistic test environments.
QA teams require representative datasets.
Analytics teams need access to production-like data.
Vendors need data for solution validation.
Yet sharing or replicating sensitive customer, patient, or financial information introduces significant risk.
Synthetic data solves this problem by creating statistically representative data that preserves utility while eliminating exposure to real individuals.
However, not all synthetic data solutions are built for enterprise complexity.
The Limitation of Single-Table Synthetic Data
Many organizations begin their synthetic data journey with a straightforward use case: generating synthetic records for machine learning or analytics.
While useful, these approaches often focus on individual tables rather than entire relational systems.
The challenge becomes apparent when organizations attempt to recreate real-world environments.
Consider a healthcare database:
Patients
Appointments
Providers
Diagnoses
Prescriptions
Claims
Billing records
Lab results
Each table depends on multiple relationships.
The same applies to banking systems, insurance platforms, ERP environments, CRM databases, and enterprise applications.
Generating synthetic rows is relatively easy.
Maintaining foreign key integrity, preserving relationships, and ensuring realistic business logic across dozens of interconnected tables is significantly harder.
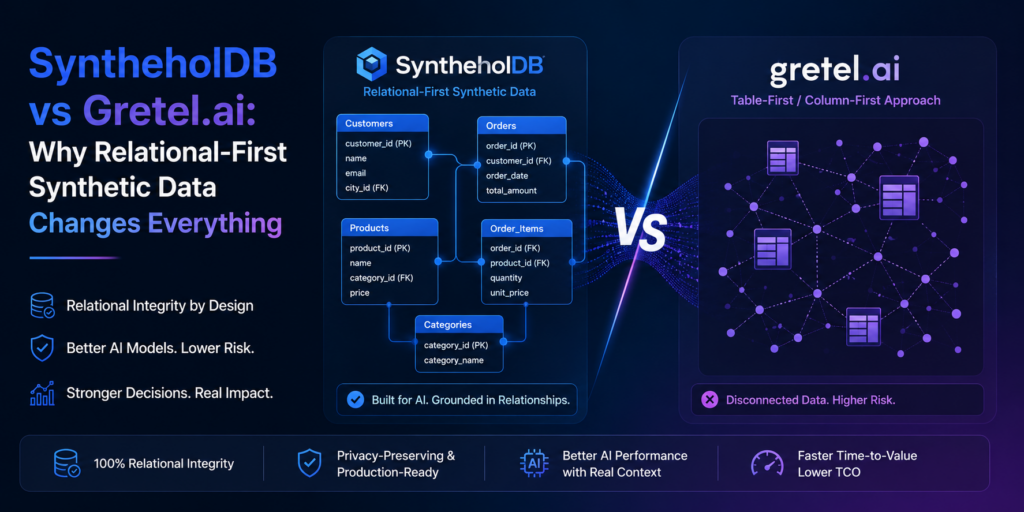
Why Synthehol DB Was Built Differently
Synthehol DB was designed specifically for organizations that need more than synthetic datasets.
It was built for synthetic databases.
Rather than focusing solely on tabular data generation, Synthehol DB creates production-like relational databases while preserving:
Foreign key relationships
Parent-child dependencies
Multi-table joins
Complex schemas
Business rules
Referential integrity
This allows engineering, QA, and analytics teams to work with realistic environments that closely mirror production systems without exposing sensitive information.
For enterprises operating large-scale applications, relational integrity isn’t optional—it’s essential.
Built for Regulated Industries
Organizations in regulated industries face unique challenges when adopting synthetic data solutions.
Compliance teams need transparency.
Security teams need validation.
Governance teams need documentation.
Synthehol DB addresses these requirements through an audit-first approach.
Every synthetic data generation run automatically includes:
Fidelity Metrics
Measure how closely synthetic data reflects the characteristics of the source data.
Utility Scores
Validate whether the synthetic data remains useful for testing, analytics, and development purposes.
Privacy Assessments
Provide evidence that sensitive information cannot be reconstructed or linked back to real individuals.
Audit Artifacts
Create documentation that can be shared with security, compliance, and governance stakeholders.
Instead of treating validation as a separate process, Synthehol DB makes it part of every generation workflow.
Enterprise Deployment Without Compromise
Many enterprises operate under strict infrastructure and security requirements.
Cloud-based solutions aren’t always an option.
Healthcare organizations, financial institutions, government agencies, and defense contractors frequently require:
On-premises deployment
Air-gapped environments
Internal-only processing
Complete infrastructure control
Synthehol DB provides native support for enterprise deployment models, including fully air-gapped environments where sensitive data never leaves organizational boundaries.
This flexibility allows enterprises to adopt synthetic data without introducing new security concerns.
Research-Driven Synthetic Data Generation
Enterprise buyers increasingly demand transparency around how synthetic data is generated.
Synthehol DB is backed by four published research papers that inform the platform’s underlying generation methodologies.
This research-driven foundation helps organizations evaluate synthetic data quality with confidence while providing visibility into the techniques used to preserve privacy and maintain utility.
For technical teams, understanding the science behind the platform is often as important as understanding the feature set.
Common Synthehol DB Use Cases
Organizations use Synthehol DB to accelerate a wide range of initiatives, including:
Software Testing
Generate realistic test databases without exposing production data.
Quality Assurance
Validate applications using production-like environments.
User Acceptance Testing
Create safe environments for business users to validate workflows.
Vendor Evaluation
Share realistic datasets with external vendors without exposing sensitive information.
Data Sharing
Enable collaboration across departments, partners, and third parties.
Analytics Development
Allow analysts to build dashboards and reports using representative datasets.
AI and Machine Learning Preparation
Generate realistic relational data environments for model development and validation.
Why Enterprises Are Looking Beyond Traditional Synthetic Data Platforms
The synthetic data market has matured rapidly.
Organizations are no longer evaluating platforms based solely on their ability to generate synthetic records.
Instead, they are asking more sophisticated questions:
Can the platform preserve complex database relationships?
Can it support large-scale enterprise schemas?
Does it provide built-in auditability?
Can it operate within regulated environments?
Does it support on-premises deployment?
Can compliance teams trust the outputs?
These questions reflect the realities of enterprise adoption.
Synthetic data is no longer an experimental technology.
It has become critical infrastructure for modern software development, testing, and AI initiatives.
Why Synthehol DB Is a Strong Gretel.ai Alternative
Organizations evaluating Gretel.ai alternatives are often searching for a platform that goes beyond synthetic datasets and supports enterprise-scale relational database generation.
Synthehol DB delivers:
Multi-table synthetic database generation
Foreign key integrity preservation
Deep relational schema support
Audit-by-default validation
Privacy and utility scoring
On-premises and air-gapped deployment
Research-backed generation methodologies
Enterprise-grade governance capabilities
For teams working with complex, regulated, production-scale environments, these capabilities can significantly reduce risk while accelerating innovation.
Get Started with Synthehol DB
Synthetic data should eliminate bottlenecks—not create new ones.
Whether you’re building test environments, enabling secure data sharing, validating vendor solutions, or accelerating AI development, Synthehol DB helps organizations generate realistic, compliant, production-like databases in minutes.
Start free and generate your first multi-table synthetic database today.
Because when relationships matter, synthetic rows aren’t enough.
If you landed here, you’re probably either evaluating Tonic.ai and wondering if there’s a better option, or you’re already using it and something isn’t working the way you expected. Either way, this is the honest breakdown you need before making a decision.
What Tonic.ai Does and Where It Falls Short
Tonic.ai built its reputation as a data de-identification and subsetting platform. Its core workflow takes a production database, runs it through masking and transformation rules, and outputs a safer copy for non-production use. More recently, the Fabricate product added AI-driven generation from scratch.
That sounds like it solves the test data problem. In practice, for most engineering teams, it solves a different problem — and the gap creates real friction.
The production data dependency. Tonic.ai’s foundational workflow requires connecting to a production database and processing real records through a masking pipeline. The output is de-identified, but real PII still travels through the pipeline to get there. Under GDPR, HIPAA, and CCPA, that pipeline still needs a data processing agreement, a third-party risk assessment, and ongoing audit documentation. For teams who thought they were eliminating compliance risk around test data, this is the moment they realize they’ve reorganized it instead.
Pricing built for enterprise procurement. Tonic.ai is priced for compliance departments with formal procurement cycles. For a small engineering team that needs to seed a staging environment or a CI pipeline, the budget conversation becomes a blocker for what should be a developer productivity decision. There is no free tier, no self-serve start, and no path to getting started without a sales conversation.
Complexity that doesn’t match the use case. Teams that want to generate realistic relational test data from scratch — without de-identifying anything, without connecting to production, without configuring masking rules — consistently find Tonic.ai heavier than what they actually need. The platform was built for a different problem and it shows in the workflow.
Relational generation gaps. Tonic.ai’s de-identification workflow preserves relationships from a source database because those relationships already exist in the data it’s masking. When generating from scratch, maintaining foreign key integrity across multiple linked tables with correct cardinality and realistic value distributions across those relationships is not what the platform was primarily designed for.
Why SyntheholDB Is the Right Answer
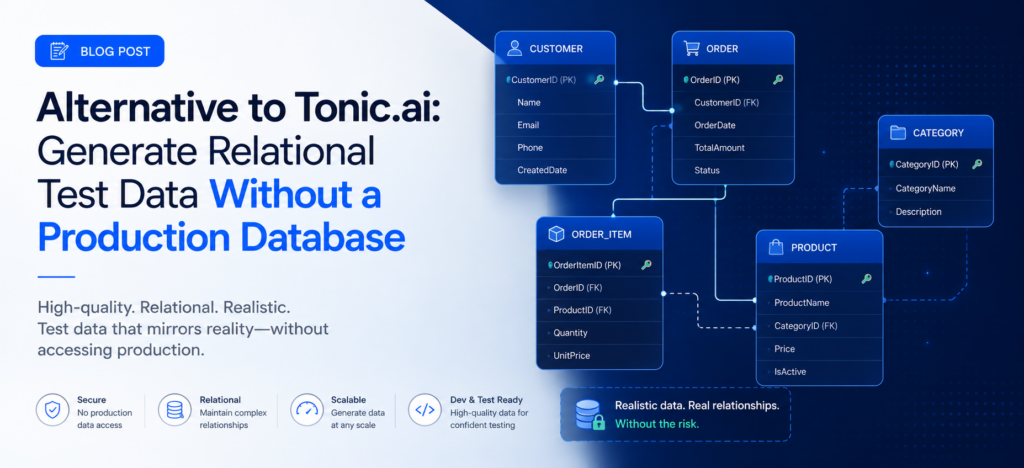
SyntheholDB was designed from the ground up for the problem Tonic.ai doesn’t cleanly solve: generating realistic, relationally consistent synthetic databases from scratch, with zero real data at any step in the workflow.
There is no production database connection. No source data required. No masking rules to configure. No real records processed anywhere in the pipeline. You describe what you need and the platform generates it.
Plain English schema input. Describe your data model conversationally — “a Users table, an Orders table, and a Products table, with orders linking to users, and order values scaling with customer tenure” — and the AI schema builder creates the full structure. No SQL, no YAML, no configuration files. The schema builder infers column types, proposes foreign key relationships, and lets you review and adjust before generation runs.
Native relational integrity. Foreign keys resolve correctly across every linked table. Cardinality is tunable. Value distributions reflect the business logic you specify — not the distributions of a production database you may not want to touch. If 15% of your users should have incomplete profiles and 8% should be in a failed payment state, you specify that and the generator respects it across the entire relational structure.
Starter schema blueprints. Not starting from scratch? The platform includes pre-built schema blueprints for e-commerce, SaaS, fintech, healthcare EHR, banking ledger, global workforce HRIS, and IoT device fleet — each with realistic row count proportions already configured and ready to generate from immediately.
Zero PII in the workflow — by architecture, not by policy. Because SyntheholDB generates from schema descriptions rather than processing real data, the compliance posture is categorically different. There is no data transfer to document, no third-party processing to assess, and no production records to track through a non-production pipeline. Your legal team’s conversation about test data environments goes from ongoing audit work to a one-time architectural sign-off.
A free tier that actually lets you start. The free tier is live at db.synthehol.ai with no credit card required. Upload a schema CSV, pick a starter blueprint, or describe your first table in plain English and have a seeded relational database in under five minutes. Paid plans start at $19/month for teams that need higher row counts, API access, or advanced export formats.
Compliance certifications that cover regulated industries. SOC 2 Type II, ISO 27001, HIPAA, and GDPR compliance are built into the platform — not roadmap items. For teams in healthcare, fintech, and regulated SaaS, this is the certification stack that makes procurement conversations fast.
The Workflow Comparison
In Tonic.ai, every generation starts with a production database connection. You configure masking rules, run the pipeline, and export a transformed copy. When your schema changes, you reconfigure the masking rules and rerun. The workflow is repeatable but it always starts from real data.
In SyntheholDB, every generation starts with a description. You describe the schema, configure the distributions, and generate. When your schema changes, you update the description and regenerate. The output drops directly into your staging database, CI pipeline, or demo environment as a CSV or SQL dump. Nothing in the pipeline ever touches a real customer record.
For developer environments, the change is friction — seeding a local database goes from waiting on a de-identification pipeline to having data in under a minute. For CI pipelines, the change is consistency — deterministic seed configuration means every test run starts from the same realistic, relational dataset without manual fixture maintenance. For demo environments, the change is confidence — demo data tuned to look like a prospect’s industry without any compliance risk attached to how it got there.
The Migration Path
If you’re currently using Tonic.ai and want to move your test data workflow to SyntheholDB, the migration is straightforward.
Export your schema structure from your current database — column names and types, no data values needed. Import the CSV into SyntheholDB. Review the inferred foreign key relationships and adjust anything that didn’t infer correctly. Configure the distributions and edge case populations you want in your test data. Export as CSV or SQL dump and drop it into the seed step that previously consumed a Tonic.ai output.
Once your seed scripts run cleanly against SyntheholDB output, the production database connection that fed the previous workflow can be removed entirely. That removal is the moment the compliance posture changes permanently — there is no longer any pipeline that processes real records for non-production purposes.
Most engineering teams complete the full migration in two to four days. The longest part is the distribution configuration step, not because it’s technically difficult, but because it’s the first time most teams have explicitly thought about what their test data should actually look like.
Start Here
The free tier is live at db.synthehol.ai. No credit card, no sales call, no enterprise procurement process. Upload your schema CSV or describe your first table in plain English and have a seeded relational database in under five minutes.
The workflow you’ve been looking for doesn’t start with a production database connection. It starts with a description.
Last week, I had a deeply insightful conversation with a group of seasoned life sciences professionals—CROs, clinical trial auditors, quality leads, and physicians with decades of experience across leading pharma and biotech companies spanning Phase I through Phase III trials.
The conversation wasn’t about technology for technology’s sake. It was about a real, recurring operational problem that every healthcare and pharma organization faces:
You know the use case. You have the hypothesis. You can see the value. But you can’t access the data.
The Data Gridlock in Healthcare
Here’s what we heard, condensed into three painful realities:
1. Data scarcity when you need it most
Clinical trials often begin with limited patient enrollment. Imagine running a Phase I trial targeting 20 subjects, but only 4 have enrolled. Your analytics, modeling, and monitoring workflows are starved for data. You can’t validate your assumptions. You can’t test your systems. You can’t demonstrate proof-of-concept to stakeholders.
2. Regulatory and privacy barriers that delay everything
HIPAA. IRB approvals. Internal governance layers. Cross-organizational data sharing agreements. Even when data exists, accessing it for development, testing, vendor demos, or AI training can take months—if it’s approved at all.
The reality? Teams often know exactly what they need. But compliance frameworks make “just get me the data” nearly impossible.
3. Data movement challenges across organizations
For vendor teams, CROs, or product builders working across multiple sponsors, moving data between environments is blocked by governance. Teams end up rebuilding the same logic over and over because data can’t travel safely.
What We Learned: The Real Demand Signal
During the call, one participant asked a clarifying question that crystallized the entire conversation:
“If we have a trial with only 4 enrolled subjects but need to simulate 20 or 30 for feasibility analysis—can synthetic data do that?”Yes. That’s exactly the kind of problem synthetic data solves.
But more importantly, the question revealed something deeper: the market needs a way to generate enterprise-grade, relational, statistically realistic datasets without requiring production data access at all.
How SyntheholDB Solves This
This is where SyntheholDB becomes strategically valuable for healthcare, pharma, and med-tech organizations.
1. Generate data from prompts, schemas, or limited samples
SyntheholDB gives teams three flexible starting points:
Extrapolate from small samples (like those 4 enrolled patients) to create larger, realistic cohorts
Generate from schema alone when you have the structure but can’t access live data
Build from natural language prompts when designing new trials, monitoring workflows, or analytics use cases from scratch
2. Preserve referential integrity across tables
SyntheholDB understands table relationships, foreign keys, dependencies, and generation order.
When you generate a synthetic EHR database with patients, encounters, diagnoses, prescriptions, and trial eligibility tables, the system ensures:
Encounters only exist when patients exist
Prescriptions correctly link encounters, medications, and patients
The result? Data that behaves like real data when you query it, join it, or run analytics on it.
3. Tune correlations for domain realism
SyntheholDB includes a correlation studio where teams can inspect and adjust relationships between columns and across tables.
Healthcare data is full of domain-specific relationships: age correlates with comorbidity count, state influences treatment access, encounter type affects prescription frequency.
Teams can see those relationships, adjust them, and regenerate until the synthetic data matches the real-world behavior they need to model.
4. Catalog-level transparency for audit readiness
Every generation comes with a detailed catalog:
Row, column, and table counts
Table reference mappings
Distribution summaries and relationship validation
Version history for complete traceability
For regulated environments where auditability and transparency are non-negotiable, this built-in governance layer accelerates adoption.
Real Use Cases Healthcare Teams Are Solving
Clinical Trials & Research
Trial feasibility analysis when enrollment is incomplete
Synthetic control arms for faster comparisons
Protocol simulation to test scenarios across demographics, sites, or treatment variations
Imbalance detection and bias mitigation before trials scale
Operational & Monitoring Workflows
CRO reporting and analytics dashboards that can’t use live sponsor data
Audit scenario testing for quality, compliance, and site monitoring teams
Vendor product development when clients can’t share production PHI
AI, Analytics & Product Innovation
EHR-like sandbox data for training AI models, testing algorithms, and validating hypotheses
Faster pilot cycles because teams don’t wait months for data access approvals
Client-facing demos that look real without exposing sensitive information
Cross-Organizational Collaboration
Data sharing between sponsors, CROs, and health systems when governance blocks live data movement
Multi-site analytics where pooling real data is legally or operationally impossible
Why This Matters Now
The healthcare and life sciences industry is at an inflection point. AI, real-world evidence, precision medicine, and patient-centric trials all depend on faster access to better data.
Synthetic data infrastructure—when built for enterprise needs—decouples innovation speed from data access friction.
It lets teams:
Build before they have full data access
Test before they have scale
Prove value before they expose risk
Collaborate across organizational boundaries safely
Final Thought: Solving for Clinical Data Specifically
During the call, a seasoned auditor emphasized:
“Can we focus the discussion on clinical data specifically? That’s where we see the most friction.” That singular focus—clinical data, not just any healthcare data—is where real commercial value lives.
Because clinical data is:
The hardest to access
The most regulated
The most valuable for innovation
The highest priority for AI and analytics initiatives
If you’re leading innovation, analytics, AI, or product development in healthcare, pharma, or med-tech—and data access is your bottleneck—SyntheholDB is built to solve this.
SyntheholDB provides enterprise-grade synthetic data infrastructure designed specifically for regulated environments where privacy, speed, and statistical fidelity can’t be compromised.
If you’ve been evaluating synthetic data platforms, you’ve probably come across Gretel.ai. It’s well-funded, well-known, and has built a solid reputation in the privacy and ML training data space. So why are engineering teams in regulated industries increasingly choosing SyntheholDB instead?
The answer comes down to one fundamental difference in philosophy: Gretel.ai was built to synthesize data you already have. SyntheholDB was built to generate data you need — from scratch, with full relational integrity, in minutes, without touching a single real record.
That distinction matters more than it sounds.
What Gretel.ai Does Well
Gretel.ai is a mature, capable platform with a strong focus on differential privacy, PII detection, and ML model training data[cite:99][cite:103]. Its core workflow takes an existing dataset as input, learns its statistical properties, and outputs a synthetic version that preserves those patterns while protecting individual privacy.
For teams that have data and need a privacy-safe version of it, Gretel.ai does that job well. It supports tabular data, text, and time-series formats, offers a Python SDK and API for integration, and has enterprise-grade infrastructure for large-scale generation[cite:108]. Reviews consistently highlight the quality of its synthetic output and the depth of its privacy tooling[cite:103].
But that workflow — input real data, get synthetic data back — carries a hidden assumption that limits its usefulness for a significant portion of what engineering teams actually need synthetic data for.
The Problem Gretel.ai’s Workflow Creates
To use Gretel.ai, you need to feed it real data first.
That means real customer records, real patient data, or real transaction histories have to travel through your pipeline, get uploaded to a third-party platform, be processed through their models, and then come back out the other side as synthetic output. Even if the end result is private, the journey involves real PII at every step.
For teams operating under HIPAA, GDPR, or CCPA, this creates a compliance question that many organisations would rather not have to answer[cite:99]. You’re not eliminating PII exposure from your data pipeline — you’re adding a step to it. Your security team still has to evaluate the third-party risk. Your legal team still has to review the data processing agreement. Your engineers still have to handle, transfer, and manage real records before any synthetic data is generated.
This is a real friction point, especially for teams in healthcare, fintech, and any regulated B2B SaaS product where moving production data to an external platform triggers a formal review process.
There’s a second limitation that surfaces in developer workflows specifically. Gretel.ai’s pricing starts at $295 per month for team plans[cite:99], with usage-based costs layered on top. For an individual developer or a small engineering team that needs realistic test data for a staging environment or a CI pipeline, that price point is a significant barrier to adoption — especially when the use case doesn’t require privacy preservation of existing data, just realistic generation of new data.
What SyntheholDB Does Differently
SyntheholDB starts from a completely different place. There is no input data. No real records. No upload, no transfer, no third-party processing of sensitive information.
You describe your schema — in plain English, or by uploading a CSV — and SyntheholDB generates a fully synthetic relational database from scratch. The output reflects the statistical distributions and business logic you specify, not the patterns of an existing real dataset. Foreign keys resolve correctly across linked tables. Value distributions reflect the parameters you set. Edge cases are built into the generation, not discovered later in production.
The built-in PII scan runs before every export — not to detect PII you uploaded, but to catch any generated value that accidentally resembles a real-world identifier before it ever leaves the tool. The compliance posture is fundamentally different because the architecture is fundamentally different. There is nothing to breach, nothing to audit, and nothing to disclose.
Head-to-Head: Where Each Platform Wins
Dimension
Gretel.ai
SyntheholDB
Core workflow
Synthesize from existing real data
Generate from schema description, no real data required
Relational integrity
Limited — primarily flat tabular datasets
Native — foreign keys resolve across linked tables by design
PII exposure in workflow
Real data must be uploaded and processed
Zero real data at any step
Plain English input
No — requires structured data input or SDK
Yes — describe your schema conversationally
Time to first dataset
Hours to days (model training required)
Under 5 minutes
Pricing entry point
$295/month for team plans[cite:99]
Free tier, no credit card required
Primary use case
ML training data privacy, data sharing
Dev/staging/CI seed data, demo environments, ML evaluation data
Compliance posture
Reduces PII in output
Eliminates PII from entire workflow
Differential privacy
Yes — built-in DP mechanisms[cite:96]
Built-in PII detection scan pre-export
Enterprise infrastructure
Yes — cloud-scale, GCP partnership[cite:108]
Free tier to paid, focused on developer workflow
The Use Case Gap Nobody Talks About
Gretel.ai’s documentation, pricing, and product design all point toward a specific buyer: a data science or ML team that needs a privacy-safe version of an existing dataset for model training or sharing with external partners[cite:104][cite:108].
That is a real and valuable use case. But it’s not the use case most engineering teams face day-to-day.
The majority of synthetic data problems in production engineering teams aren’t about privacy-preserving copies of real datasets. They’re about:
Seeding a staging environment with realistic data that doesn’t come from production
Generating test data for a CI pipeline that breaks as soon as it uses real records
Building a demo environment that looks convincing without carrying any compliance risk
Stress-testing an ML model against edge cases that never appear in the training distribution
For all of these use cases, starting from real data is not just unnecessary — it’s the wrong approach entirely. The whole point is to avoid real data at every step. SyntheholDB’s schema-first, generation-first architecture is purpose-built for exactly these workflows.
The Relational Integrity Difference
This is worth addressing specifically because it’s where the technical gap between the two platforms is most pronounced.
Gretel.ai’s core synthetic generation capability is designed primarily for tabular data — flat, single-table datasets where statistical fidelity to an original source is the primary objective[cite:104][cite:108]. Generating multi-table relational structures with consistent foreign key relationships across linked tables is not what the platform was designed to do.
SyntheholDB’s generation engine is built around relational integrity as a first principle. When you describe a schema with Users, Orders, and Products tables, the generator maintains referential integrity across all three — order foreign keys resolve to valid user IDs, product references are consistent, and value distributions across linked tables reflect the business logic you specified. This isn’t a feature layered on top of a tabular generator. It’s the core of how the generation engine works.
For any team working with a relational database — which is most teams — this distinction directly affects how useful the synthetic data is in practice.
Who Should Use Which Platform
Gretel.ai is the right choice if:
You have existing datasets and need privacy-safe synthetic versions for model training or external sharing
Your primary concern is differential privacy guarantees on data that already exists
You need enterprise-scale infrastructure with GCP integration and formal privacy compliance tooling
Your team has the budget for a $295/month starting point and the data science expertise to work with the SDK
SyntheholDB is the right choice if:
You need realistic relational test data without touching any production records
Your use case is staging environments, CI pipelines, demo environments, or ML evaluation datasets
You want to describe your schema in plain English and get usable data back in minutes, not days
You’re working in a regulated industry and need the compliance posture of zero real data in the workflow
You want to start free and scale as your needs grow
The Bottom Line
Gretel.ai and SyntheholDB are solving adjacent but meaningfully different problems. Gretel.ai is a privacy-preservation platform for teams that have real data and need a safer version of it. SyntheholDB is a relational data generation platform for teams that need realistic data without ever touching real records.
For engineering teams in regulated industries who are tired of the compliance conversation that comes with every staging environment, every demo setup, and every test data request — SyntheholDB’s architecture eliminates the problem at the source rather than managing it downstream.
The free tier is live at db.synthehol.ai. No credit card, no model training, no real data required. Describe your first schema and have a seeded relational database in under five minutes.
We are excited to share that SyntheholDB, our synthetic database platform, has officially launched on Product Hunt.
For many engineering and data teams, the only practical way to get “realistic” test data has been to clone production into staging and hope nothing goes wrong. SyntheholDB exists so that is no longer the only option.
Our goal is simple:
Let teams test like it is production – without ever copying production data.
Why We Launched SyntheholDB
Over the past year, we have spent a lot of time with teams in fintech, insurance, healthtech, and enterprise SaaS. Almost all of them described the same tension:
Security and privacy teams are increasingly uncomfortable with production clones in non‑production environments.
Data and ML teams cannot trust toy datasets or clean CSVs to reveal real failure modes.
DevOps and SRE teams are accountable for reliability on environments that do not behave like the real thing.
Most existing synthetic data tools were built to generate flat tables for analytics or isolated model training. That is useful, but it does not solve the end‑to‑end test environment problem.
SyntheholDB takes a different path. Instead of “here is a synthetic file,” the product is designed to say:
“Here is a synthetic database that matches your real schema and relationships, and behaves like your system – without any real customer records.”
Product Hunt felt like the right place to introduce that idea to a wider group of builders and to invite honest feedback from people testing it on their own stacks.
What SyntheholDB Does
SyntheholDB is built for teams who work with real systems, not just notebooks.
Schema‑first synthetic databases
You start by bringing your existing schema into SyntheholDB. Think of the databases behind:
a payments or lending system
an insurance policy and claims system
a healthtech application with patients, visits, and claims
a multi‑tenant SaaS product with accounts, users, events, and usage
SyntheholDB understands your tables, keys, and relationships, then generates synthetic data that respects them.
Constraint‑aware generation
Instead of filling tables with random values, SyntheholDB preserves:
primary and foreign keys
uniqueness and referential integrity
basic business rules (for example: no claim without a policy, no order without a customer)
The result is a database your existing services, pipelines, and tests can actually run against.
Relational, not just tabular
Real applications depend on how entities relate across many tables. SyntheholDB generates linked synthetic data across those tables, so you can:
run end‑to‑end integration and regression tests
simulate realistic workflows and edge cases
keep the shape and behavior of production without reusing its data
Why Product Hunt, and Why Now
We launched on Product Hunt on May 6, 2026 at 12:01 AM PT to do three things:
Put SyntheholDB in front of a broader community of engineers, data scientists, ML practitioners, DevOps, and founders.
Collect public, honest feedback from people willing to test it on their own schemas.
Refine our positioning around a simple message:“If cloning prod into staging is currently your only option, SyntheholDB is the alternative.”
Throughout launch day, our team spent time:
helping users connect schemas and generate their first synthetic databases
answering architecture, security, and compliance questions
learning where SyntheholDB already fits and where it still needs to grow
Those conversations are already feeding into the product roadmap.
Even though launch day has passed, our Product Hunt page is still the best place to see how others are using SyntheholDB and to add your own review.
Who SyntheholDB Is For
SyntheholDB is designed for teams who:
Own transactional or operational databases with many interconnected tables
Need to keep sensitive production data out of dev, test, and staging
Want non‑production environments that are trustworthy, not just approximate
Are building AI, data, or analytics products that fail if the underlying data does not look like reality
We see strong interest from:
Fintech and banking – payments, ledgers, lending, fraud