If you landed here, you’re probably either evaluating Tonic.ai and wondering if there’s a better option, or you’re already using it and something isn’t working the way you expected. Either way, this is the honest breakdown you need before making a decision.
What Tonic.ai Does and Where It Falls Short
Tonic.ai built its reputation as a data de-identification and subsetting platform. Its core workflow takes a production database, runs it through masking and transformation rules, and outputs a safer copy for non-production use. More recently, the Fabricate product added AI-driven generation from scratch.
That sounds like it solves the test data problem. In practice, for most engineering teams, it solves a different problem — and the gap creates real friction.
The production data dependency. Tonic.ai’s foundational workflow requires connecting to a production database and processing real records through a masking pipeline. The output is de-identified, but real PII still travels through the pipeline to get there. Under GDPR, HIPAA, and CCPA, that pipeline still needs a data processing agreement, a third-party risk assessment, and ongoing audit documentation. For teams who thought they were eliminating compliance risk around test data, this is the moment they realize they’ve reorganized it instead.
Pricing built for enterprise procurement. Tonic.ai is priced for compliance departments with formal procurement cycles. For a small engineering team that needs to seed a staging environment or a CI pipeline, the budget conversation becomes a blocker for what should be a developer productivity decision. There is no free tier, no self-serve start, and no path to getting started without a sales conversation.
Complexity that doesn’t match the use case. Teams that want to generate realistic relational test data from scratch — without de-identifying anything, without connecting to production, without configuring masking rules — consistently find Tonic.ai heavier than what they actually need. The platform was built for a different problem and it shows in the workflow.
Relational generation gaps. Tonic.ai’s de-identification workflow preserves relationships from a source database because those relationships already exist in the data it’s masking. When generating from scratch, maintaining foreign key integrity across multiple linked tables with correct cardinality and realistic value distributions across those relationships is not what the platform was primarily designed for.
Why SyntheholDB Is the Right Answer
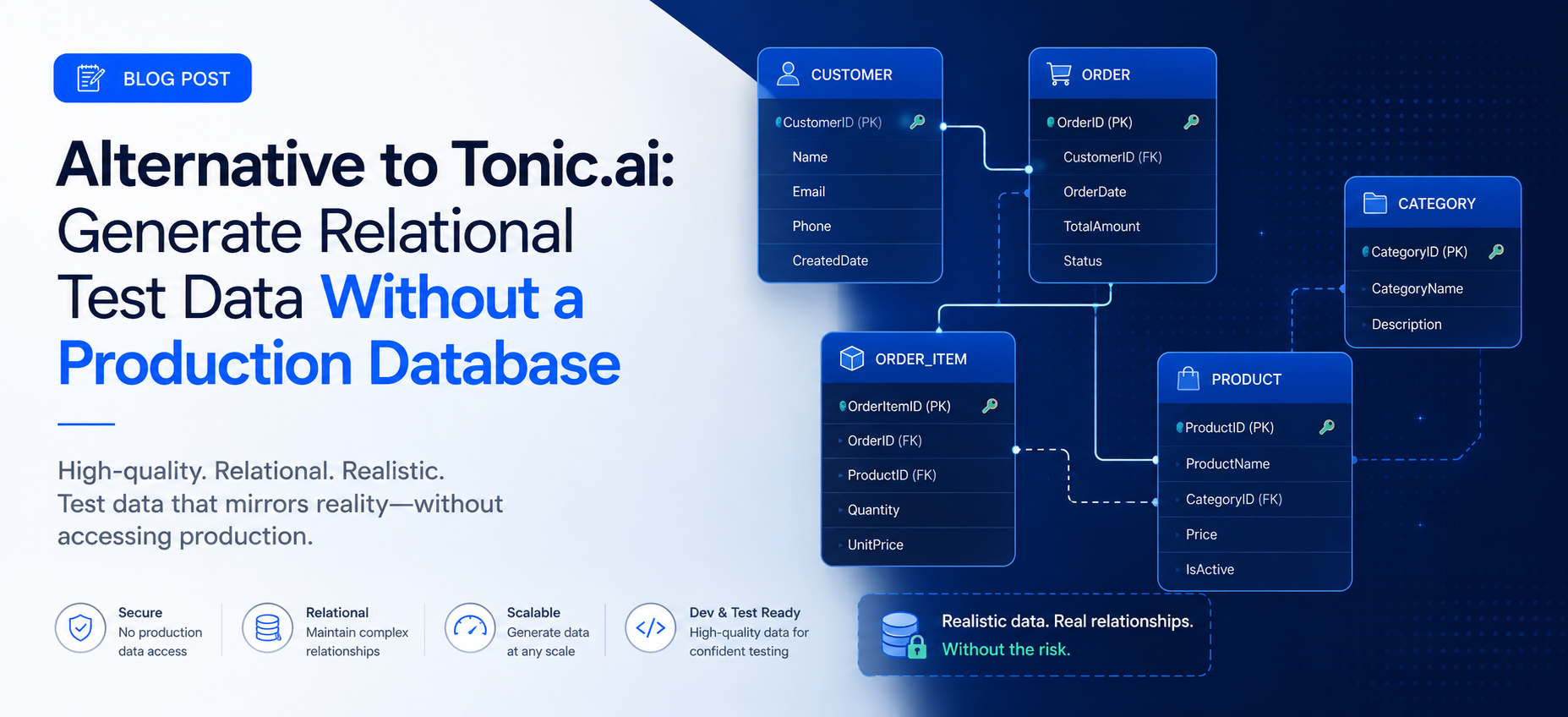
SyntheholDB was designed from the ground up for the problem Tonic.ai doesn’t cleanly solve: generating realistic, relationally consistent synthetic databases from scratch, with zero real data at any step in the workflow.
There is no production database connection. No source data required. No masking rules to configure. No real records processed anywhere in the pipeline. You describe what you need and the platform generates it.
Plain English schema input. Describe your data model conversationally — “a Users table, an Orders table, and a Products table, with orders linking to users, and order values scaling with customer tenure” — and the AI schema builder creates the full structure. No SQL, no YAML, no configuration files. The schema builder infers column types, proposes foreign key relationships, and lets you review and adjust before generation runs.
Native relational integrity. Foreign keys resolve correctly across every linked table. Cardinality is tunable. Value distributions reflect the business logic you specify — not the distributions of a production database you may not want to touch. If 15% of your users should have incomplete profiles and 8% should be in a failed payment state, you specify that and the generator respects it across the entire relational structure.
Starter schema blueprints. Not starting from scratch? The platform includes pre-built schema blueprints for e-commerce, SaaS, fintech, healthcare EHR, banking ledger, global workforce HRIS, and IoT device fleet — each with realistic row count proportions already configured and ready to generate from immediately.
Zero PII in the workflow — by architecture, not by policy. Because SyntheholDB generates from schema descriptions rather than processing real data, the compliance posture is categorically different. There is no data transfer to document, no third-party processing to assess, and no production records to track through a non-production pipeline. Your legal team’s conversation about test data environments goes from ongoing audit work to a one-time architectural sign-off.
A free tier that actually lets you start. The free tier is live at db.synthehol.ai with no credit card required. Upload a schema CSV, pick a starter blueprint, or describe your first table in plain English and have a seeded relational database in under five minutes. Paid plans start at $19/month for teams that need higher row counts, API access, or advanced export formats.
Compliance certifications that cover regulated industries. SOC 2 Type II, ISO 27001, HIPAA, and GDPR compliance are built into the platform — not roadmap items. For teams in healthcare, fintech, and regulated SaaS, this is the certification stack that makes procurement conversations fast.
The Workflow Comparison
In Tonic.ai, every generation starts with a production database connection. You configure masking rules, run the pipeline, and export a transformed copy. When your schema changes, you reconfigure the masking rules and rerun. The workflow is repeatable but it always starts from real data.
In SyntheholDB, every generation starts with a description. You describe the schema, configure the distributions, and generate. When your schema changes, you update the description and regenerate. The output drops directly into your staging database, CI pipeline, or demo environment as a CSV or SQL dump. Nothing in the pipeline ever touches a real customer record.
For developer environments, the change is friction — seeding a local database goes from waiting on a de-identification pipeline to having data in under a minute. For CI pipelines, the change is consistency — deterministic seed configuration means every test run starts from the same realistic, relational dataset without manual fixture maintenance. For demo environments, the change is confidence — demo data tuned to look like a prospect’s industry without any compliance risk attached to how it got there.
The Migration Path
If you’re currently using Tonic.ai and want to move your test data workflow to SyntheholDB, the migration is straightforward.
Export your schema structure from your current database — column names and types, no data values needed. Import the CSV into SyntheholDB. Review the inferred foreign key relationships and adjust anything that didn’t infer correctly. Configure the distributions and edge case populations you want in your test data. Export as CSV or SQL dump and drop it into the seed step that previously consumed a Tonic.ai output.
Once your seed scripts run cleanly against SyntheholDB output, the production database connection that fed the previous workflow can be removed entirely. That removal is the moment the compliance posture changes permanently — there is no longer any pipeline that processes real records for non-production purposes.
Most engineering teams complete the full migration in two to four days. The longest part is the distribution configuration step, not because it’s technically difficult, but because it’s the first time most teams have explicitly thought about what their test data should actually look like.
Start Here
The free tier is live at db.synthehol.ai. No credit card, no sales call, no enterprise procurement process. Upload your schema CSV or describe your first table in plain English and have a seeded relational database in under five minutes.
The workflow you’ve been looking for doesn’t start with a production database connection. It starts with a description.
Leave a Reply